Chapter 2: Design Methods
Principles, failure analysis, selection logic, and key dimensions for cybersecurity monitoring system design
2.1 Design Principles & References
Effective cybersecurity monitoring system design is grounded in a set of executable engineering principles that have been validated through operational experience across diverse enterprise environments. These principles are not abstract ideals but actionable constraints that shape every architectural decision, from telemetry source selection to SOAR playbook design. Each principle is accompanied by a reference type indicating its primary justification — whether SOC best practice, engineering necessity, compliance requirement, or operational scaling concern.
- Use-case first, not data-hoarding: Onboard telemetry by prioritized scenarios and assets. Collecting everything without classification creates unsustainable costs and noise that defeats the purpose of monitoring. Reference: SOC best practice + cost control.
- Time is a security control: Enforce NTP/PTP across all sources, collectors, and SIEM components; monitor drift continuously. Correlation accuracy depends entirely on synchronized timestamps. Reference: Engineering necessity for correlation.
- Common schema or consistent mapping: Adopt ECS-like field normalization; version-control parsers as code. Inconsistent field naming prevents cross-source correlation. Reference: Interoperability.
- Asset and identity binding is mandatory: Every event must map to asset_id and user_id when possible. Without this binding, triage requires manual lookup and MTTR increases dramatically. Reference: Operational triage.
- Tiered retention by criticality: Hot/warm/archive storage tiers plus WORM for key logs. Flat retention is either too expensive or too short for compliance. Reference: Compliance + cost.
- Least privilege and separation of duties: Collectors, SIEM admins, and SOC analysts must have separate roles; break-glass access must be audited. Reference: Insider risk.
- Defense-in-depth observation points: Deploy visibility at edge, east-west, management network, and cloud simultaneously. Modern lateral movement bypasses perimeter-only monitoring. Reference: Modern threat landscape.
- Severity = Impact × Confidence × Exposure: Standardize severity scoring to reduce noise and prioritize analyst attention. Reference: SOC scaling.
- Automation with guardrails: All automated response actions must have approval gates, rollback capability, and dry-run modes. Automation without guardrails causes outages. Reference: Availability protection.
- Closed-loop governance: Every incident must yield tuning and hardening tasks; track closure rates. Reference: Continuous improvement.
- Immutable evidence: Log integrity and chain-of-custody are prerequisites for investigations and legal proceedings. Reference: Audit/legal.
2.2 Failure Causes & Recommendations
Monitoring system failures rarely result from a single catastrophic event. More commonly, they arise from a cascade of design oversights that individually seem minor but collectively create significant blind spots or operational failures. The following table maps the most common failure causes to their underlying mechanisms, operational results, and actionable recommendations.
| Failure Cause | Mechanism | Result | Recommendation |
|---|---|---|---|
| No asset inventory | Events cannot be prioritized by business impact | Alert flood; analysts cannot distinguish critical from trivial | CMDB sync + criticality tags before onboarding sources |
| Poor time sync | Correlation joins fail; event ordering is unreliable | Missed multi-step attacks; false negative rate increases | Drift monitoring + enforcement; alert on >2s drift |
| Collector single point of failure | Outage creates complete visibility gap for a zone | Blind spots during incidents; audit gaps | HA collector pairs + disk buffering + health monitoring |
| Unparsed logs | Raw fields are useless for correlation rules | Low fidelity detections; high false positive rate | Parser QA + schema standards + corpus testing |
| No severity model | All alerts treated with equal urgency | Analyst burnout; critical alerts buried in noise | Multi-tier alerting with asset criticality scoring |
| No response integration | All containment actions are manual | High MTTR; inconsistent response quality | SOAR/ITSM workflows with approval gates |
| No tuning cycle | Detection rules degrade as environment changes | Rising false positive rate; analyst trust erodes | Monthly tuning cadence with KPI-driven targets |
| No integrity controls | Evidence can be tampered with or disputed | Audit failure; legal proceedings compromised | WORM storage + log signatures + admin audit |
2.3 Core Design & Selection Logic
The design selection process follows a structured decision framework that begins with business objectives and works through environment characteristics, scale requirements, and automation needs to arrive at an appropriate architecture pattern. This decision tree prevents the common mistake of selecting a SIEM product before understanding the deployment context and operational model.
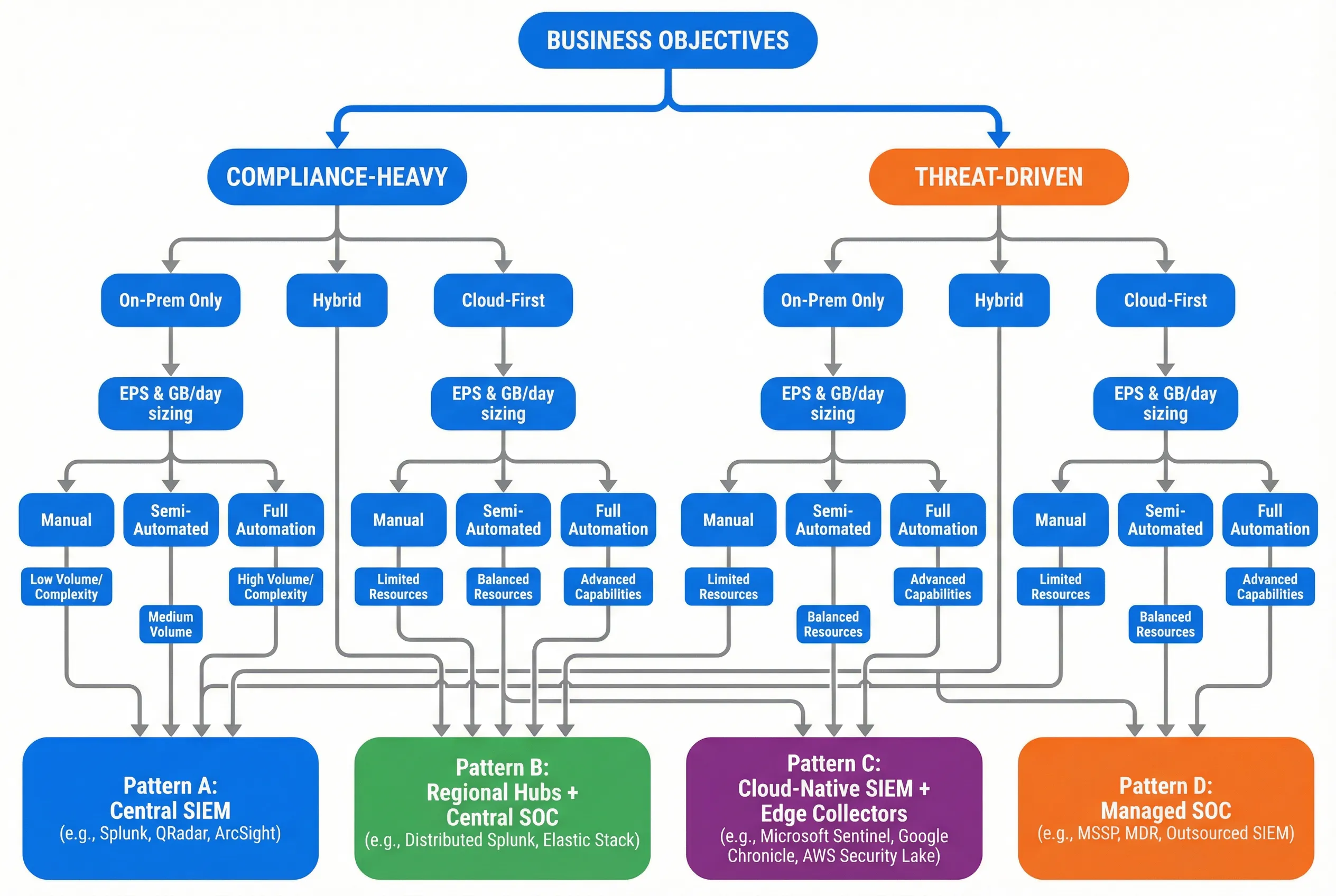
Decision Steps
- Identify top 12–20 detection use-cases mapped to MITRE ATT&CK techniques and business risk. This scope definition prevents scope creep and focuses telemetry onboarding.
- Define asset tiers and "crown jewels." Identify the 5–15% of assets that, if compromised, would cause the most significant business impact. These drive observation point placement and retention requirements.
- Choose observation points and minimum telemetry per tier. Map each detection use-case to the telemetry sources required to detect it. Avoid collecting sources that don't contribute to any use-case.
- Size ingestion/storage and define retention tiers. Use the calculators in Chapter 9 to derive EPS, GB/day, and storage requirements for each tier.
- Choose SIEM/SOAR integration pattern and approval model. Select from the four architecture patterns based on the decision tree, then define the approval workflow for automated actions.
- Define acceptance tests using simulated attack paths. For each detection use-case, define a test scenario that validates end-to-end detection and response capability.
2.4 Key Design Dimensions
Every monitoring system design must be evaluated across seven key dimensions that collectively determine whether the system will be effective, sustainable, and compliant over its operational lifetime. Optimizing for only one or two dimensions while ignoring others leads to systems that are technically impressive but operationally unviable.
| Dimension | Key Considerations | Design Implications | Common Trade-offs |
|---|---|---|---|
| Performance / Experience | Ingestion latency, analyst workflow speed, search response time | Hot storage sizing, indexing strategy, UI optimization | More indexing improves search but increases storage cost |
| Stability / Reliability | HA architecture, buffering, disaster recovery, failover time | Collector pairs, message bus, SIEM cluster, backup SIEM | Higher HA increases infrastructure cost and complexity |
| Maintainability | Connector lifecycle, parser versioning, content CI/CD | Version control for all content; canary rollout; rollback | More automation requires more upfront engineering investment |
| Compatibility / Expansion | Multi-vendor support, cloud integration, API-first design | Connector abstraction layer; schema versioning | Vendor-specific features may conflict with portability |
| LCC / TCO | Licensing, storage, staffing, tuning effort, training | Tiered storage; use-case scoped ingestion; automation | Lower license cost may mean higher staffing cost |
| Energy / Environment | Storage tiering efficiency, data center PUE, cloud vs on-prem | Archive to object storage; decommission unused sources | Cloud reduces on-prem energy but may increase data transfer cost |
| Compliance / Certification | Audit trails, retention periods, privacy controls, certifications | WORM storage, access logs, data masking, retention policies | Compliance requirements may mandate longer retention than operationally needed |
Key insight: The most successful monitoring deployments treat the design process as iterative — starting with a minimum viable detection scope, validating it with acceptance tests, and expanding coverage in subsequent phases. Attempting to onboard all sources simultaneously before validating the core pipeline leads to high noise, poor quality, and analyst disengagement.